Do you really need that ref?
Updated: 2017/03/08 - Using an (atom) with a single thread is basically as fast as a loop with no ref. This also gives us the benefit if having something deref’able outside the loop. (See update towards the bottom of the post).
In some research I’ve been doing, I’ve found that using a simple single threaded loop for business logic with a recur statement is blisteringly fast compared to the overhead of using a ref and dosync. Furthermore, it can simplify code.
Consider the following scenario. We have an application that has some internal state. It is a purely message-drive application. That is, it receives messages from other systems, does some processing, and sends some outgoing events.
Here’s how it might look in the “let’s use a ref” world:
(defonce ^:private my-state (ref {}))
(defn- process-message!
"Alters the given state, and returns a vector of outgoing messages."
[state msg]
(let [outgoing-messages (ref [])]
(dosync
(alter state assoc (:id msg) msg)
(commute outgoing-messages conj {:stored (:id msg))))
@outgoing-messages))
(defn- process-messages
"Starts a go-loop to listen on incoming, and alter the provided state."
[state incoming outgoing]
(go-loop []
(if-let [msg (<! incoming)]
(let [out-msgs (process-message! state msg)]
(>! outgoing out-msgs)
(recur)))))The big advantage of having the ref stored separately is that we can ‘deref’ that state at any time and get a current view of what’s inside. But there are classes of applications where being able to do this is either infrequent, or not required. Using a dosync or even an atom/swap! to cater for this small-percentage scenario introduces unnecessary overhead - both in terms of code complexity and performance.
So how would we manage this without using any mutable state at all on our main thread? Consider the following alternative:
(defn- process-message
"Returns [new-state outgoing-msgs]"
[state msg]
[(assoc (:id msg) msg) [{:stored (:id msg)}]])
(defn- main-loop [incoming outgoing]
(thread
(loop [state {}]
(if-let [msg (<!! incoming)]
(let [[next-state outgoing-msgs] (process-message state msg)]
(>!! outgoing outgoing-msgs)
(recur next-state))))))Slight problem - that internal state can no longer be referenced easily from the rest of the app.
But it’s only a slight problem. We can exploit the immutability here - we can hand off a snapshot to the rest of the application without worrying about anything else screwing with our state.
We can do this by introducing another message type for our system to process, just as it would any other business logic. Personally I like this approach to diagnostics/monitoring. We treat it as we would any other business event/requirement. Meaning that monitoring is a first-class citizen of our application, not an after-thought.
Let’s see how that might look:
(defmulti process-message
"Multi-method, dispatches on :type of second argument.
Returns vector of [next-state outgoing-events]."
(fn [_ x] (:type x)))
(defmethod process-message ::STORE
[state msg]
[(assoc (:id msg) msg) [{:stored (:id msg)}]])
(defmethod process-message ::SNAPSHOT
[state msg]
(go (>! (:chan msg) state)) ;; Asynchronous send
[state []])
(defn- main-loop [incoming outgoing]
(thread
(loop [state {}]
(if-let [msg (<!! incoming)]
(let [[next-state outgoing-msgs] (process-message state msg)]
(>!! outgoing outgoing-msgs)
(recur next-state))))))Cool - so at any moment, we can retrieve our internal state by sending a message with a :type of
::SNAPSHOT, and including a channel to receive the state on. Then we listen on that channel for
the snapshot.
Finally - lies, damned lies and micro-benchmarks :-) On my laptop (i7-6600U @ 2.6ghz, 16gb memory), this is how the picture looks. For completeness - I included an additional test using an atom instead of a ref/dosync. The source code to reproduce this result is available here.
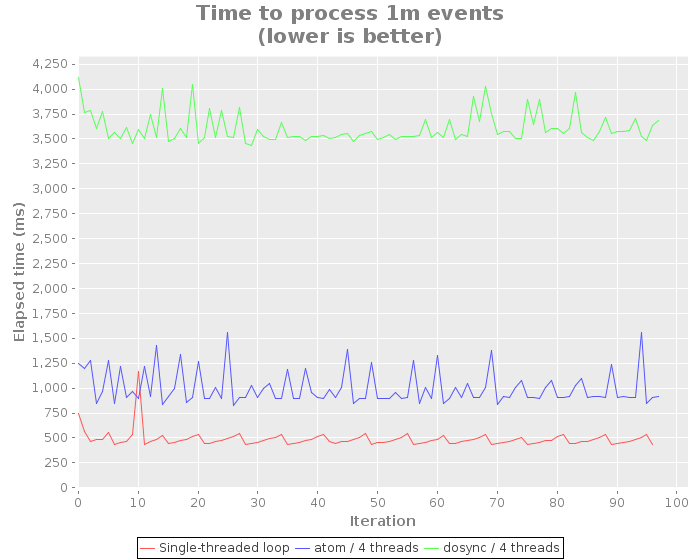
What the above shows us very clearly is that using dosync has quite a bit of overhead compared to using a simple atom or no concurrency primitives at all. The simple loop processes 1 million events usually under 500ms. Using an atom and 4 threads hovers around 1000ms, but using dosync shoots us consistently above 3500ms.
I do appreciate the beauty of dosync in applications where STM is a natural fit. But for me at least - until I feel its absolutely needed, I’ll probably be sticking with a simple loop.
So the next time you’re working the internal structure of your application - I’d urge you to ask yourself - do you really need that ref?
UPDATE: 2017/03/08
More recently, in the course of working on another piece of work, I noticed that there wasn’t a huge difference between using an atom with a single thread and a loop without a ref. So I decided to revisit this code and add tests for using the refs with a single thread. Results below:
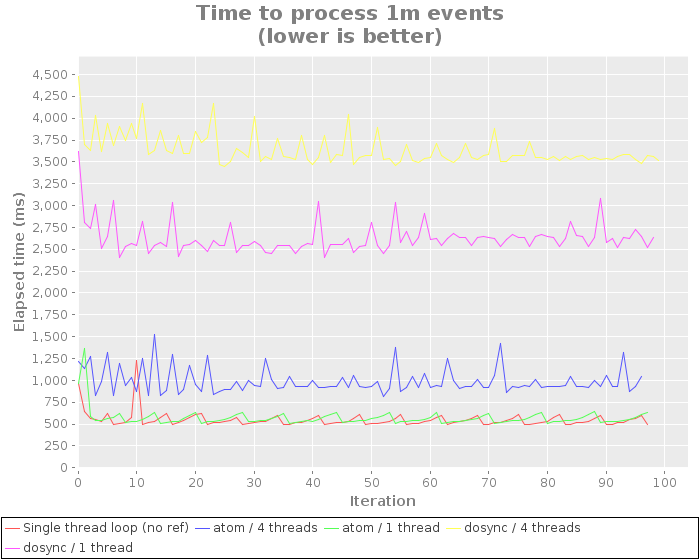
In this later piece of work, I’ve actually preferred the single-thread-with-atom approach. There isn’t a huge performance difference as can be seen in the above test, plus gives us the benefits of being able to deref externally.